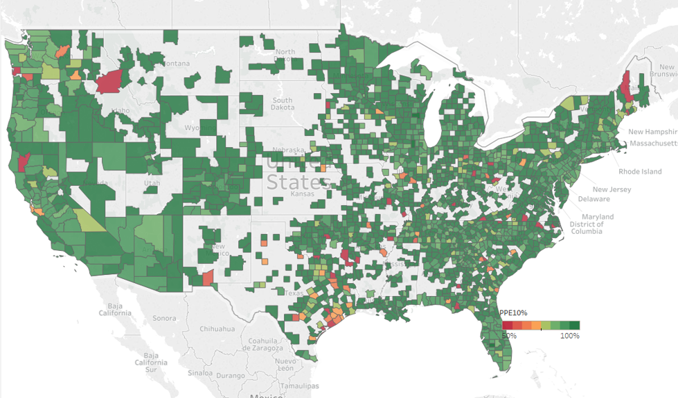
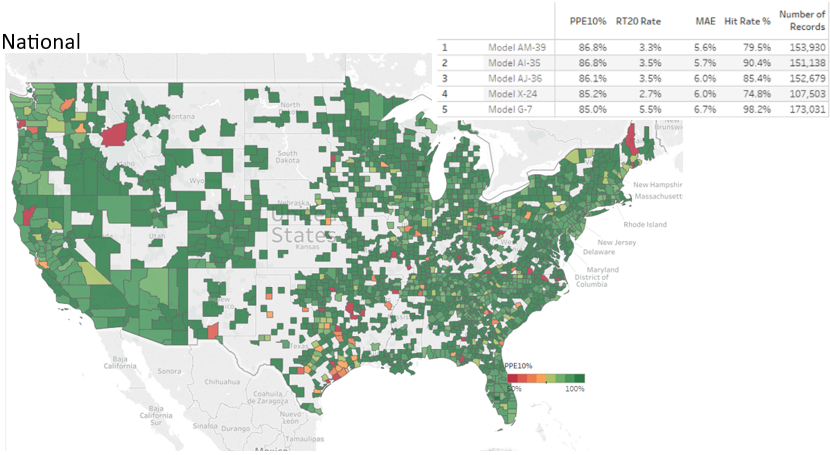
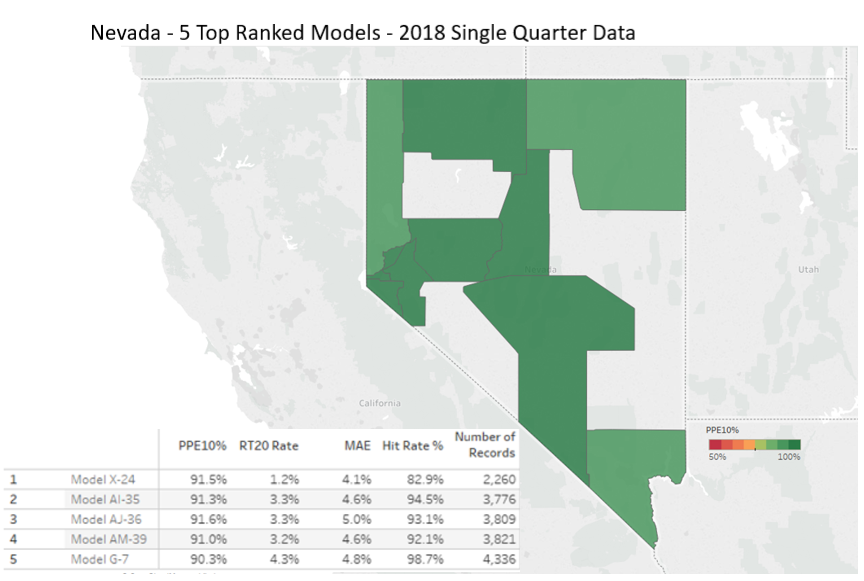
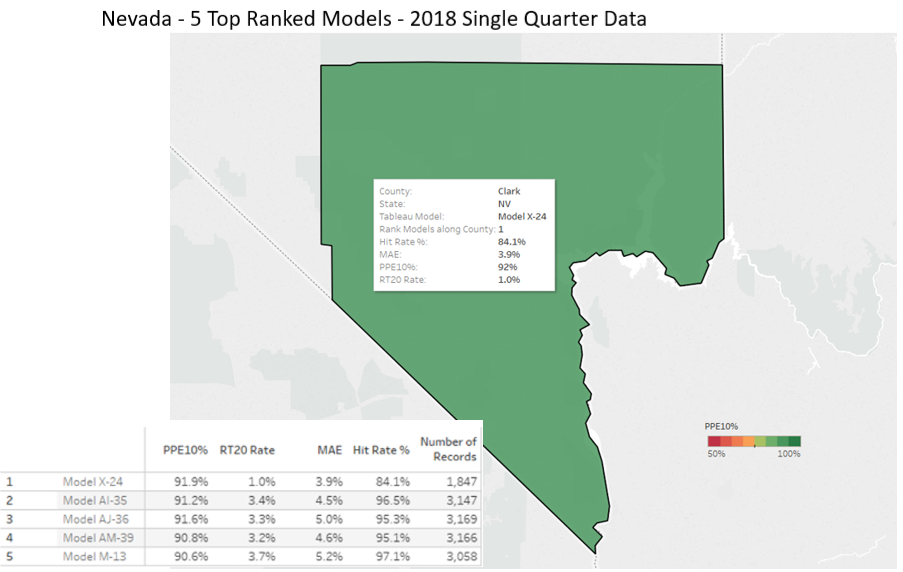
As the publisher of the AVMNews, we felt compelled to respond to the Brookings’ very thorough whitepaper on AVMs (Automated Valuation Models) published on October 12, 2023, and share our thoughts on the recommendations and insights presented therein.
First and foremost, I would like to acknowledge the thoroughness and dedication with which Brookings conducted their research. Their whitepaper contains valuable observations, clear explanations and wise recommendations that unsurprisingly align with our own perspective on AVMs.
Here’s our stance on key points from Brookings’ whitepaper:
- Expanding Public Transparency: We wholeheartedly support increased transparency in the AVM industry. In fact, Lee’s recent service on the TAF IAC AVM Task Force led to a report recommending greater transparency measures. Transparency not only fosters trust but also enhances the overall reliability of AVMs.
- Disclosing More Information to Affected Individuals: We are strong advocates for disclosing AVM accuracy and precision measures to the public. Lee’s second Task Force report also recommended the implementation of a universal AVM confidence score. This kind of information empowers individuals with a clearer understanding of AVM results.
- Guaranteeing Evaluations Are Independent: Ensuring the independence of evaluations is paramount. Compliance with this existing requirement should be non-negotiable, and we fully support this recommendation.
- Encouraging the Search for Less Discriminatory AVMs: Promoting the development and use of less discriminatory AVMs aligns with our goals. We view this as a straightforward step toward fairer AVM practices.
Regarding Brookings’ additional points 5, 6, and 7, we find them to be aspirational but not necessarily practical in the current landscape. In the case of #6, regulating Zillow, it appears that existing and proposed regulations adequately cover entities like Zillow, provided they use AVMs in lending.
While we appreciate the depth of Brookings’ research, we would like to address a few misconceptions within their paper:
- Lender Grade vs. Platform AVMs: We firmly believe that there is a distinction between lender-grade and platform AVMs, as evidenced by our testing and assessments. Variations exist not only between AVM providers but also within the different levels of AVMs offered by a single provider.
- “AVM Evaluators… Are Not Demonstrably Informing the Public:” We take exception to this statement. We actively contribute to public knowledge through articles, analyses, newsletters (AVMNews and our State of AVMs), quarterly GIF, a comprehensive Glossary, and participation in industry groups, task forces. We also serve the public by making AVM education available, and we would have been more than willing to collaborate or consult with Brookings during their research.
But, we’re obligated not to just give away our analysis or publish it. Our partners in the industry provide us their value estimates and we provide our analysis back to them. It’s a major way in which they improve, because they’re able to see 1) an independent test of accuracy, and 2) a comparison to other AVMs. They can see where they’re being beaten, which means opportunity for improvement. But, in order to participate, they require some confidentiality to protect their IP and reputation.
We should comment on the concept of independence that Brookings emphasized. Independent evaluation is exceedingly important in our opinion, as the only independent AVM evaluator. Brookings mentioned in passing that Mercury is not independent, but they also mentioned Fitch as an independent evaluator. We agree with Brookings that a vendor who also sells, builds, resells, uses or advocates for certain AVMs may be biased (or may appear to be biased) in auditing them; validation must be able to “effectively challenge” the models being tested.
We do not believe Fitch satisfies ongoing independent testing, validation and documentation of testing which requires resources with the competencies and influences to effectively challenge AVM models. Current guidelines require validation to be performed in real-world conditions, to be ongoing, and to be reported on at least annually. When there are changes to the models, the business environment or the marketplace, the models need to be re-validated.
Fitch’s assessment of AVM providers is focused on each vendor’s model testing results, review of management and staff experience, data sourcing, technology effectiveness and quality control procedures. Fitch’s methodology of relying on analyses obtained from the AVM providers’ model testing results would not categorize them as an “independent AVM evaluator,” as reliance on testing done by the AVM providers themselves does not meet any definition of “independent” per existing regulatory guidance. AVMetrics is in no way beholden to the AVM developers or the resellers in any way; we draw no income from selling, developing, or using AVM products.
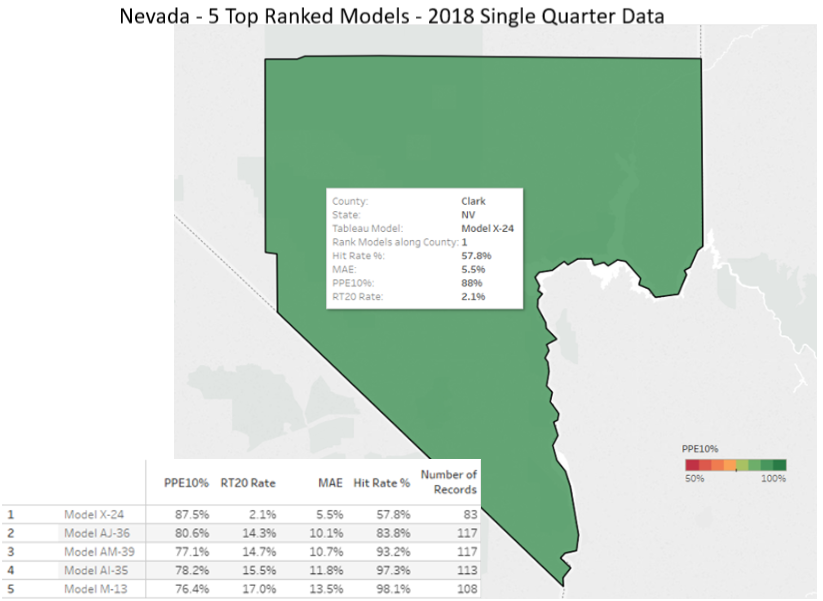
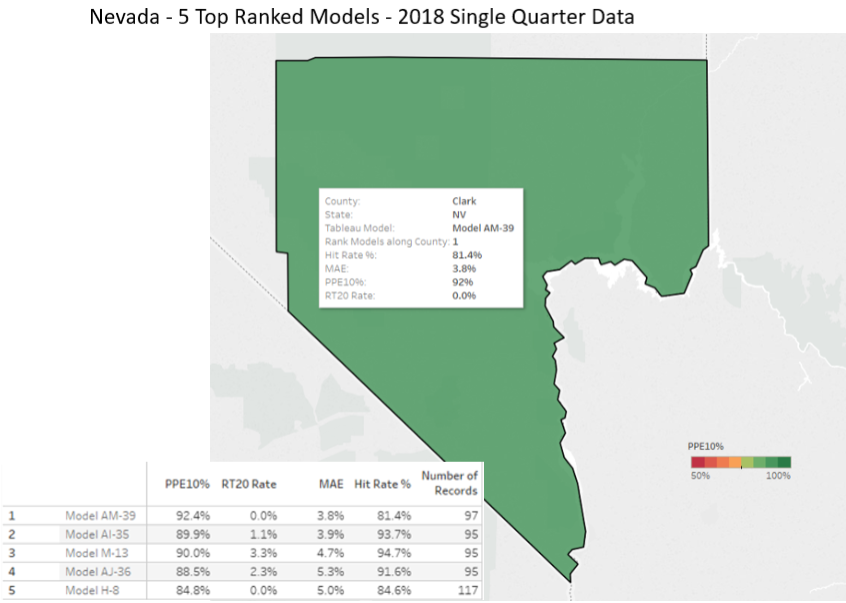
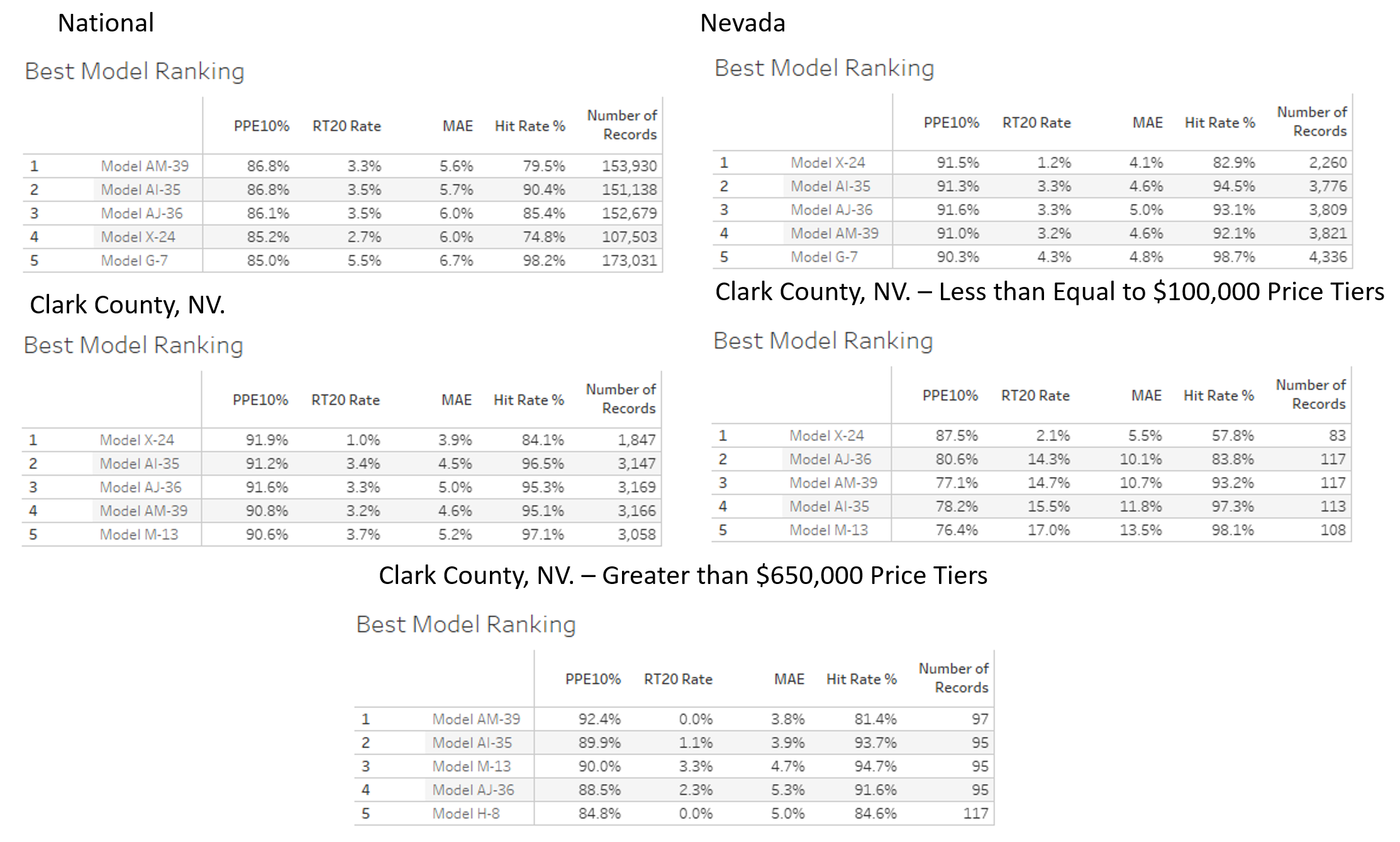
For almost two decades, we have continued to test AVMs against hundreds of thousands (sometimes millions) of transactions per quarter and use a variety of techniques to level the playing field between AVMs. We provide detailed and transparent statistical summaries and insights to our newsletter readers, and we publish charts that give insights into the depth and thoroughness of our analysis, whereas we have not observed this from other testing entities. Our research spanning eighteen years shows that even overall good-preforming models are less reliable in certain circumstances, so one of the less obvious risks that we would highlight is reliance on a “good” model that is poor in a specific geography, price level or property type. Models should be tested in each one of these subcategories in order to assess their reliability and risk profile. Identifying “reliable models” isn’t straightforward. Performance varies over time as market conditions change and models are tweaked. Performance also varies between locations, so a model that is extremely reliable overall may not be effective in a specific region. Furthermore, models that are effective overall may not be effective at all price levels, for example: low-priced entry-level homes or high-priced homes. Finally, very effective models will also produce estimates that they admit have lower confidence scores (and higher FSDs), and which should in all prudence be avoided, but without adequate testing and understanding may be inadvertently relied upon. Proper testing and controls can mitigate these problems.
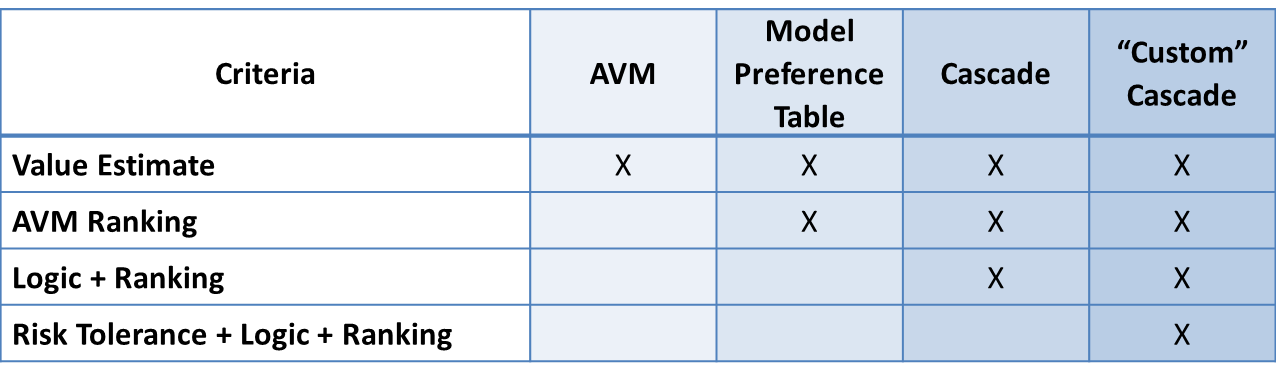
Regarding cascades, the Brookings’ paper leans on cascades as an important part of the solution for less discriminatory AVMs. We agree with Brookings: a cascade is the most sophisticated way to use AVMs. It maximizes accuracy and minimizes forecast error and risk. By subscribing to multiple AVMs, you can rank-order them to choose the highest performing AVM for each situation, which we call using a Model Preference Table™. The best possible AVM selection approach is a cascade, which combines that MPT™ with business logic to define when an AVM’s response is acceptable and when it should be set aside for the next AVM or another form of valuation. The business logic can incorporate the Forecast Standard Deviation provided by the model and the institution’s own risk-tolerance to determine when a value estimate is acceptable.
Mark Sennott (industry insider) recently published a whitepaper describing current issues with cascades, namely that some AVM resellers will give favorable positions to AVMs based on favors, pricing or other factors that do NOT include performance as evaluated by independent firms like AVMetrics. This goes to the additional transparency for which Brookings’ advocates. We’re all in favor.
We actually see a strong parallel between Mark Sennott’s whitepaper and the Brookings’ paper. Brookings makes the case to regulators, whereas Sennott was speaking to the AVM industry, but both of them argue for more transparency and responsible leadership by the industry. Sennott appears to be very prescient, in retrospect.
In order to ensure that adequate testing is done regularly we recommend that a control be implemented to create transparency around how the GSE’s or other originators are performing their testing. This could be done in a variety of ways. One method might require the GSE or lending institution to indicate their last AVM testing date on each appraisal waiver. Regardless of how it’s done, the goal would be to create a mechanism that would increase commitment to appropriate testing. The GSE’s could provide a leadership role by demonstrating how they would like lending institutions to demonstrate their independent AVM testing as required by OCC 2010-42 and 2011-12.
In conclusion, we appreciate Brookings’ dedication to asking questions and providing perspective on the AVM industry. We share their goals for transparency, fairness, and accuracy. We believe that open dialogue and collaboration by all the valuation industry participants are the keys to advancing the responsible use of AVMs.
We look forward to continuing our contributions to the AVM community and working toward a brighter future for this essential technology.